How Waiting Room makes queueing decisions on Cloudflare's highly distributed network
Almost three years ago, we launched Cloudflare Waiting Room to protect our customers’ sites from overwhelming spikes in legitimate traffic that could bring down their sites. Waiting Room gives customers control over user experience even in times of high traffic by placing excess traffic in a customizable, on-brand waiting room, dynamically admitting users as spots become available on their sites. Since the launch of Waiting Room, we’ve continued to expand its functionality based on customer feedback with features like mobile app support, analytics, Waiting Room bypass rules, and more.
We love announcing new features and solving problems for our customers by expanding the capabilities of Waiting Room. But, today, we want to give you a behind the scenes look at how we have evolved the core mechanism of our product–namely, exactly how it kicks in to queue traffic in response to spikes.
How was the Waiting Room built, and what are the challenges?
The diagram below shows a quick overview of where the Waiting room sits when a customer enables it for their website.
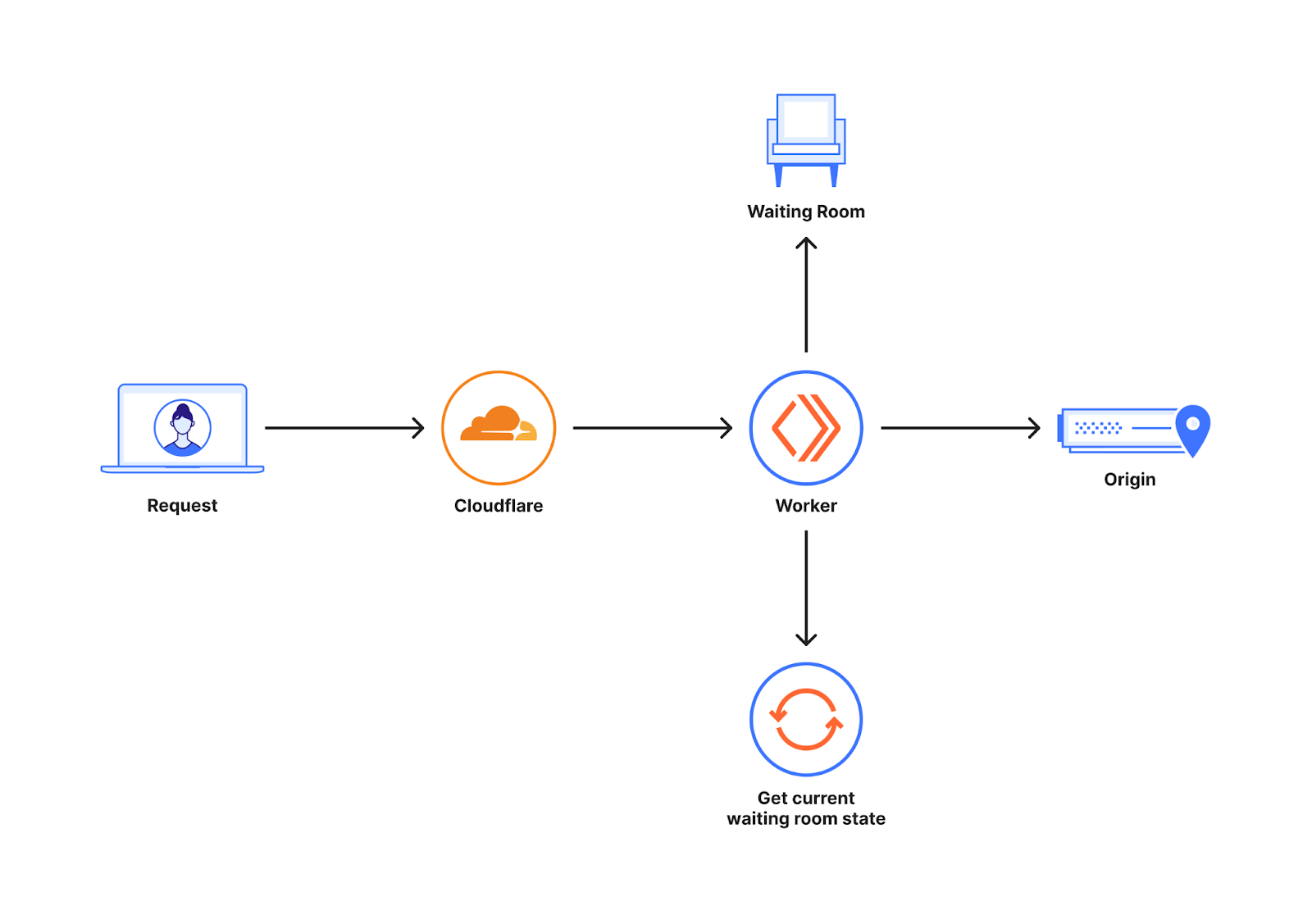
Waiting Room is built on Workers that runs across a global network of Cloudflare data centers. The requests to a customer’s website can go to many different Cloudflare data centers. To optimize for minimal latency and enhanced performance, these requests are routed to the data center with the most geographical proximity. When a new user makes a request to the host/path covered by the Waiting room, the waiting room worker decides whether to send the user to the origin or the waiting room. This decision is made by making use of the waiting room state which gives an idea of how many users are on the origin.
The waiting room state changes continuously based on the traffic around the world. This information can be stored in a central location or changes can get propagated around the world eventually. Storing this information in a central location can add significant latency to each request as the central location can be really far from where the request is originating from. So every data center works with its own waiting room state which is a snapshot of the traffic pattern for the website around the world available at that point in time. Before letting a user into the website, we do not want to wait for information from everywhere else in the world as that adds significant latency to the request. This is the reason why we chose not to have a central location but have a pipeline where changes in traffic get propagated eventually around the world.
This pipeline which aggregates the waiting room state in the background is built on Cloudflare Durable Objects. In 2021, we wrote a blog talking about how the aggregation pipeline works and the different design decisions we took there if you are interested. This pipeline ensures that every data center gets updated information about changes in traffic within a few seconds.
The Waiting room has to make a decision whether to send users to the website or queue them based on the state that it currently sees. This has to be done while making sure we queue at the right time so that the customer's website does not get overloaded. We also have to make sure we do not queue too early as we might be queueing for a falsely suspected spike in traffic. Being in a queue could cause some users to abandon going to the website. Waiting Room runs on every server in Cloudflare’s network, which spans over 300 cities in more than 100 countries. We want to make sure, for every new user, the decision whether to go to the website or the queue is made with minimal latency. This is what makes the decision of when to queue a hard question for the waiting room. In this blog, we will cover how we approached that tradeoff. Our algorithm has evolved to decrease the false positives while continuing to respect the customer’s set limits.
How a waiting room decides when to queue users
The most important factor that determines when your waiting room will start queuing is how you configured the traffic settings. There are two traffic limits that you will set when configuring a waiting room–total active users and new users per minute.The total active users is a target threshold for how many simultaneous users you want to allow on the pages covered by your waiting room. New users per minute defines the target threshold for the maximum rate of user influx to your website per minute. A sharp spike in either of these values might result in queuing. Another configuration that affects how we calculate the total active users is session duration. A user is considered active for session duration minutes since the request is made to any page covered by a waiting room.
The graph below is from one of our internal monitoring tools for a customer and shows a customer's traffic pattern for 2 days. This customer has set their limits, new users per minute and total active users to 200 and 200 respectively.
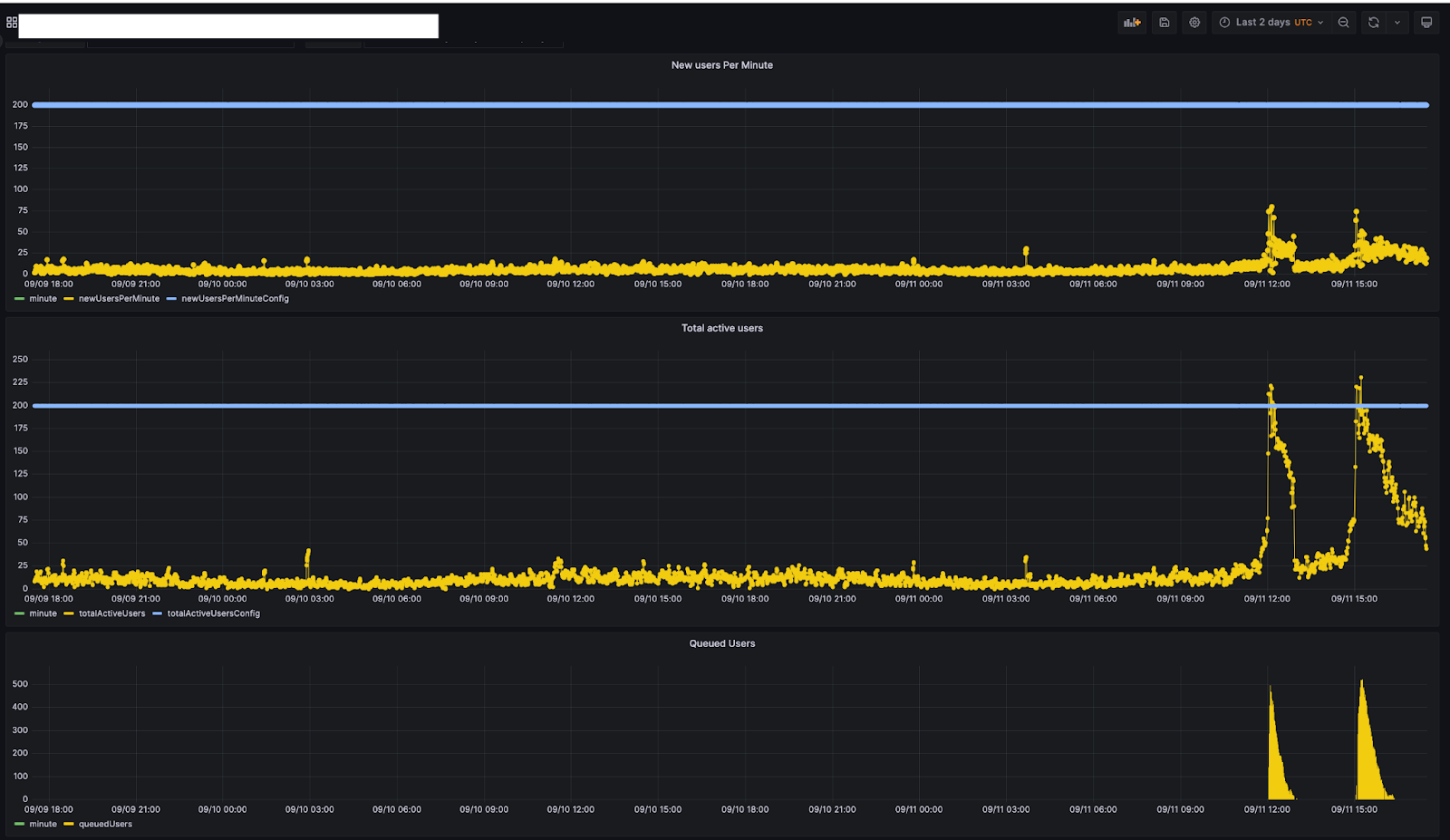
If you look at their traffic you can see that users were queued on September 11th around 11:45. At that point in time, the total active users was around 200. As the total active users ramped down (around 12:30), the queued users progressed to 0. The queueing started again on September 11th around 15:00 when total active users got to 200. The users that were queued around this time ensured that the traffic going to the website is around the limits set by the customer.
Once a user gets access to the website, we give them an encrypted cookie which indicates they have already gained access. The contents of the cookie can look like this.
{ "bucketId": "Mon, 11 Sep 2023 11:45:00 GMT", "lastCheckInTime": "Mon, 11 Sep 2023 11:45:54 GMT", "acceptedAt": "Mon, 11 Sep 2023 11:45:54 GMT"
}The cookie is like a ticket which indicates entry to the waiting room.The bucketId indicates which cluster of users this user is part of. The acceptedAt time and lastCheckInTime indicate when the last interaction with the workers was. This information can ensure if the ticket is valid for entry or not when we compare it with the session duration value that the customer sets while configuring the waiting room. If the cookie is valid, we let the user through which ensures users who are on the website continue to be able to browse the website. If the cookie is invalid, we create a new cookie treating the user as a new user and if there is queueing happening on the website they get to the back of the queue. In the next section let us see how we decide when to queue those users.
To understand this further, let's see what the contents of the waiting room state are. For the customer we discussed above, at the time "Mon, 11 Sep 2023 11:45:54 GMT", the state could look like this.
{ "activeUsers": 50,
}As mentioned above the customer’s configuration has new users per minute and total active users equal to 200 and 200 respectively.
So the state indicates that there is space for the new users as there are only 50 active users when it's possible to have 200. So there is space for another 150 users to go in. Let's assume those 50 users could have come from two data centers San Jose (20 users) and London (30 users). We also keep track of the number of workers that are active across the globe as well as the number of workers active at the data center in which the state is calculated. The state key below could be the one calculated at San Jose.
{ "activeUsers": 50, "globalWorkersActive": 10, "dataCenterWorkersActive": 3, "trafficHistory": { "Mon, 11 Sep 2023 11:44:00 GMT": { San Jose: 20/200, // 10% London: 30/200, // 15% Anywhere: 150/200 // 75% } }
}Imagine at the time "Mon, 11 Sep 2023 11:45:54 GMT", we get a request to that waiting room at a datacenter in San Jose.
To see if the user that reached San Jose can go to the origin we first check the traffic history in the past minute to see the distribution of traffic at that time. This is because a lot of websites are popular in certain parts of the world. For a lot of these websites the traffic tends to come from the same data centers.
Looking at the traffic history for the minute "Mon, 11 Sep 2023 11:44:00 GMT" we see San Jose has 20 users out of 200 users going there (10%) at that time. For the current time "Mon, 11 Sep 2023 11:45:54 GMT" we divide the slots available at the website at the same ratio as the traffic history in the past minute. So we can send 10% of 150 slots available from San Jose which is 15 users. We also know that there are three active workers as "dataCenterWorkersActive" is 3.
The number of slots available for the data center is divided evenly among the workers in the data center. So every worker in San Jose can send 15/3 users to the website. If the worker that received the traffic has not sent any users to the origin for the current minute they can send up to five users (15/3).
At the same time ("Mon, 11 Sep 2023 11:45:54 GMT"), imagine a request goes to a data center in Delhi. The worker at the data center in Delhi checks the trafficHistory and sees that there are no slots allotted for it. For traffic like this we have reserved the Anywhere slots as we are really far away from the limit.
{ "activeUsers":50, "globalWorkersActive": 10, "dataCenterWorkersActive": 1, "trafficHistory": { "Mon, 11 Sep 2023 11:44:00 GMT": { San Jose: 20/200, // 10% London: 30/200, // 15% Anywhere: 150/200 // 75% } }
}The Anywhere slots are divided among all the active workers in the globe as any worker around the world can take a part of this pie. 75% of the remaining 150 slots which is 113.
The state key also keeps track of the number of workers (globalWorkersActive) that have spawned around the world. The Anywhere slots allotted are divided among all the active workers in the world if available. globalWorkersActive is 10 when we look at the waiting room state. So every active worker can send as many as 113/10 which is approximately 11 users. So the first 11 users that come to a worker in the minute Mon, 11 Sep 2023 11:45:00 GMT gets admitted to the origin. The extra users get queued. The extra reserved slots (5) in San Jose for minute Mon, 11 Sep 2023 11:45:00 GMT discussed before ensures that we can admit up to 16(5 + 11) users from a worker from San Jose to the website.
Queuing at the worker level can cause users to get queued before the slots available for the data center
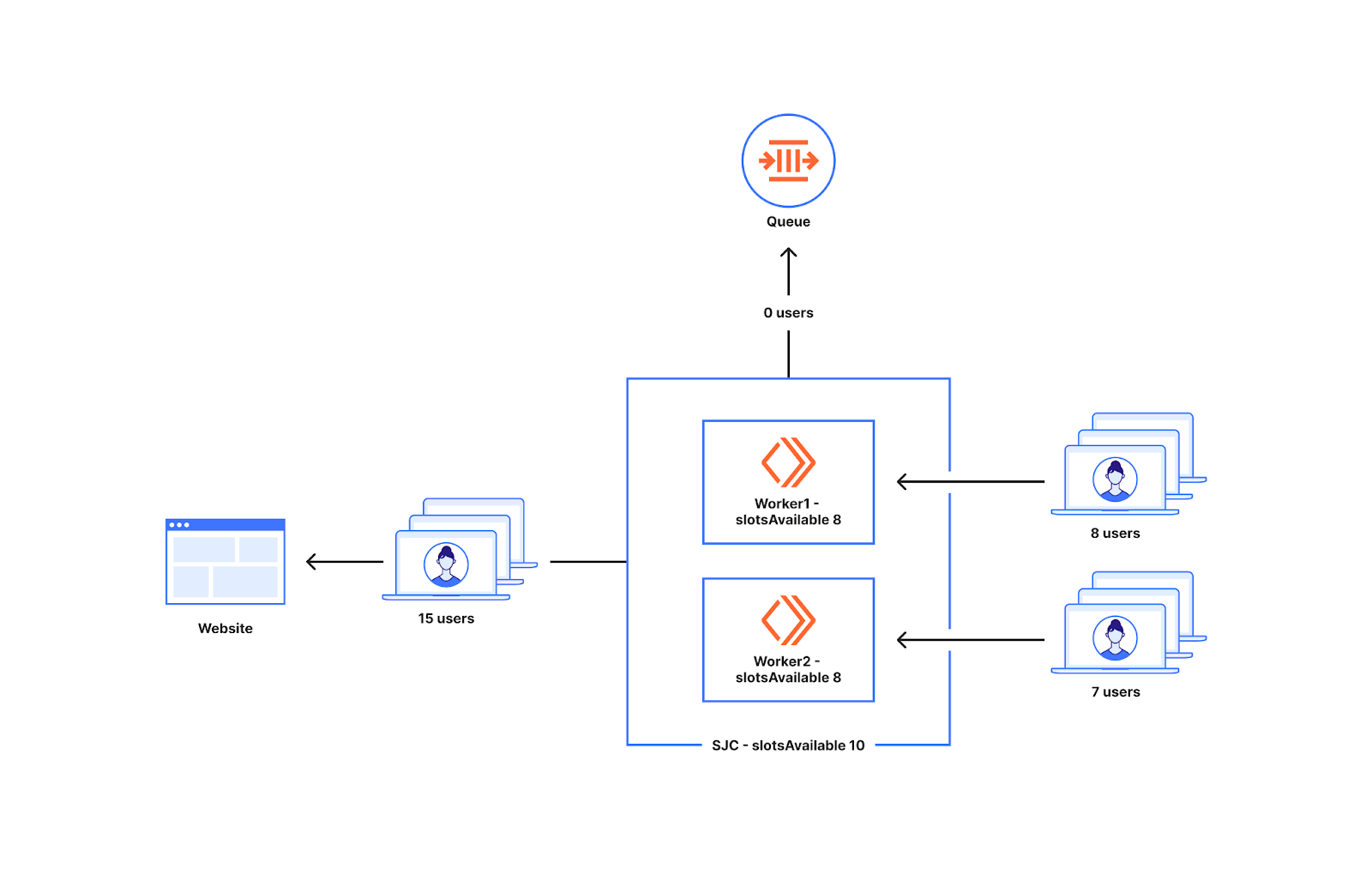
As we can see from the example above, we decide whether to queue or not at the worker level. The number of new users that go to workers around the world can be non-uniform. To understand what can happen when there is non-uniform distribution of traffic to two workers, let us look at the diagram below.
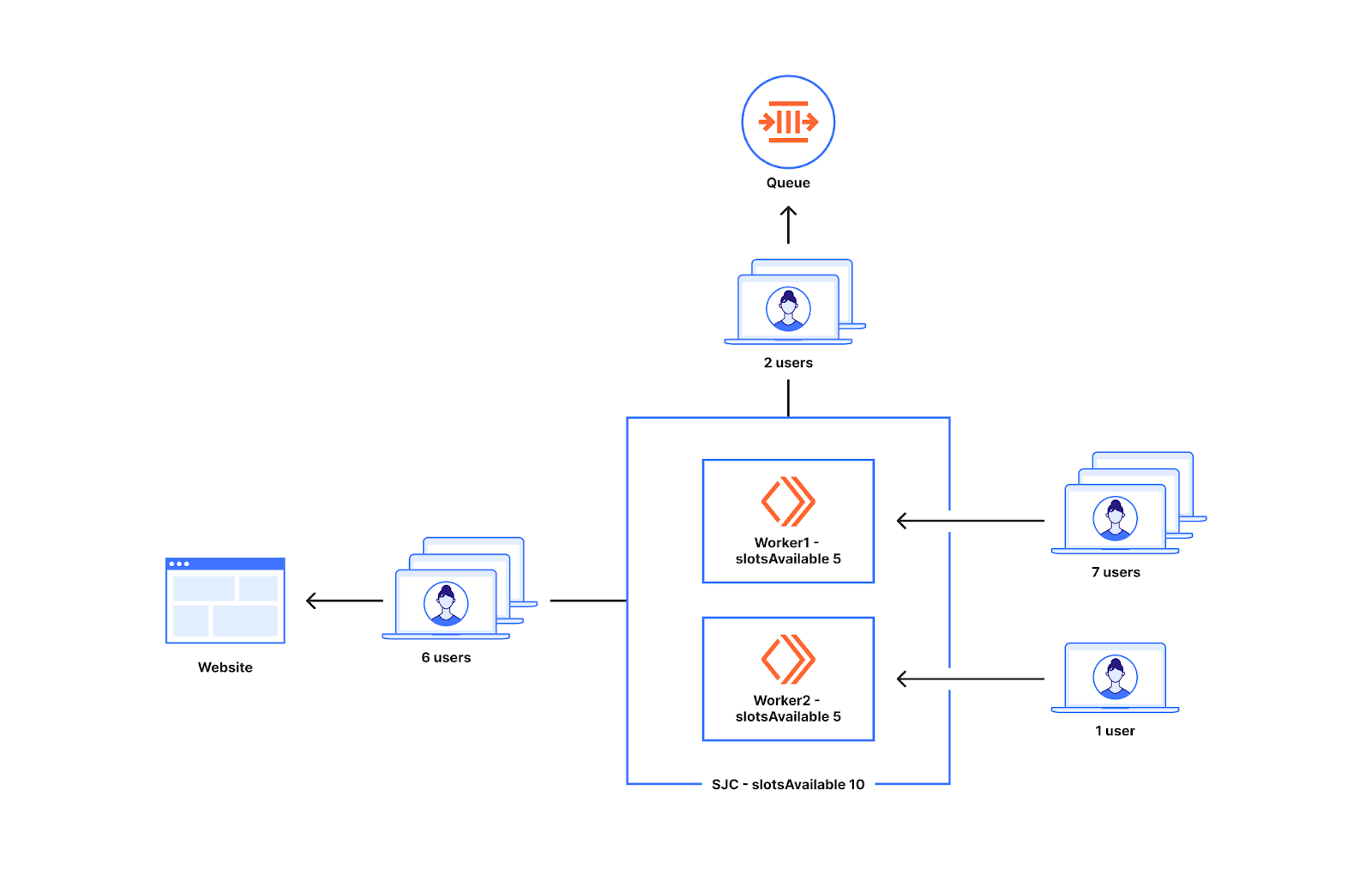
Imagine the slots available for a data center in San Jose are ten. There are two workers running in San Jose. Seven users go to worker1 and one user goes to worker2. In this situation worker1 will let in five out of the seven workers to the website and two of them get queued as worker1 only has five slots available. The one user that shows up at worker2 also gets to go to the origin. So we queue two users, when in reality ten users can get sent from the datacenter San Jose when only eight users show up.
This issue while dividing slots evenly among workers results in queueing before a waiting room’s configured traffic limits, typically within 20-30% of the limits set. This approach has advantages which we will discuss next. We have made changes to the approach to decrease the frequency with which queuing occurs outside that 20-30% range, queuing as close to limits as possible, while still ensuring Waiting Room is prepared to catch spikes. Later in this blog, we will cover how we achieved this by updating how we allocate and count slots.
What is the advantage of workers making these decisions?
The example above talked about how a worker in San Jose and Delhi makes decisions to let users through to the origin. The advantage of making decisions at the worker level is that we can make decisions without any significant latency added to the request. This is because to make the decision, there is no need to leave the data center to get information about the waiting room as we are always working with the state that is currently available in the data center. The queueing starts when the slots run out within the worker. The lack of additional latency added enables the customers to turn on the waiting room all the time without worrying about extra latency to their users.
Waiting Room’s number one priority is to ensure that customer’s sites remain up and running at all times, even in the face of unexpected and overwhelming traffic surges. To that end, it is critical that a waiting room prioritizes staying near or below traffic limits set by the customer for that room. When a spike happens at one data center around the world, say at San Jose, the local state at the data center will take a few seconds to get to Delhi.
Splitting the slots among workers ensures that working with slightly outdated data does not cause the overall limit to be exceeded by an impactful amount. For example, the activeUsers value can be 26 in the San Jose data center and 100 in the other data center where the spike is happening. At that point in time, sending extra users from Delhi may not overshoot the overall limit by much as they only have a part of the pie to start with in Delhi. Therefore, queueing before overall limits are reached is part of the design to make sure your overall limits are respected. In the next section we will cover the approaches we implemented to queue as close to limits as possible without increasing the risk of exceeding traffic limits.
Allocating more slots when traffic is low relative to waiting room limits
The first case we wanted to address was queuing that occurs when traffic is far from limits. While rare and typically lasting for one refresh interval (20s) for the end users who are queued, this was our first priority when updating our queuing algorithm. To solve this, while allocating slots we looked at the utilization (how far you are from traffic limits) and allotted more slots when traffic is really far away from the limits. The idea behind this was to prevent the queueing that happens at lower limits while still being able to readjust slots available per worker when there are more users on the origin.
To understand this let's revisit the example where there is non-uniform distribution of traffic to two workers. So two workers similar to the one we discussed before are shown below. In this case the utilization is low (10%). This means we are far from the limits. So the slots allocated(8) are closer to the slotsAvailable for the datacenter San Jose which is 10. As you can see in the diagram below, all the eight users that go to either worker get to reach the website with this modified slot allocation as we are providing more slots per worker at lower utilization levels.
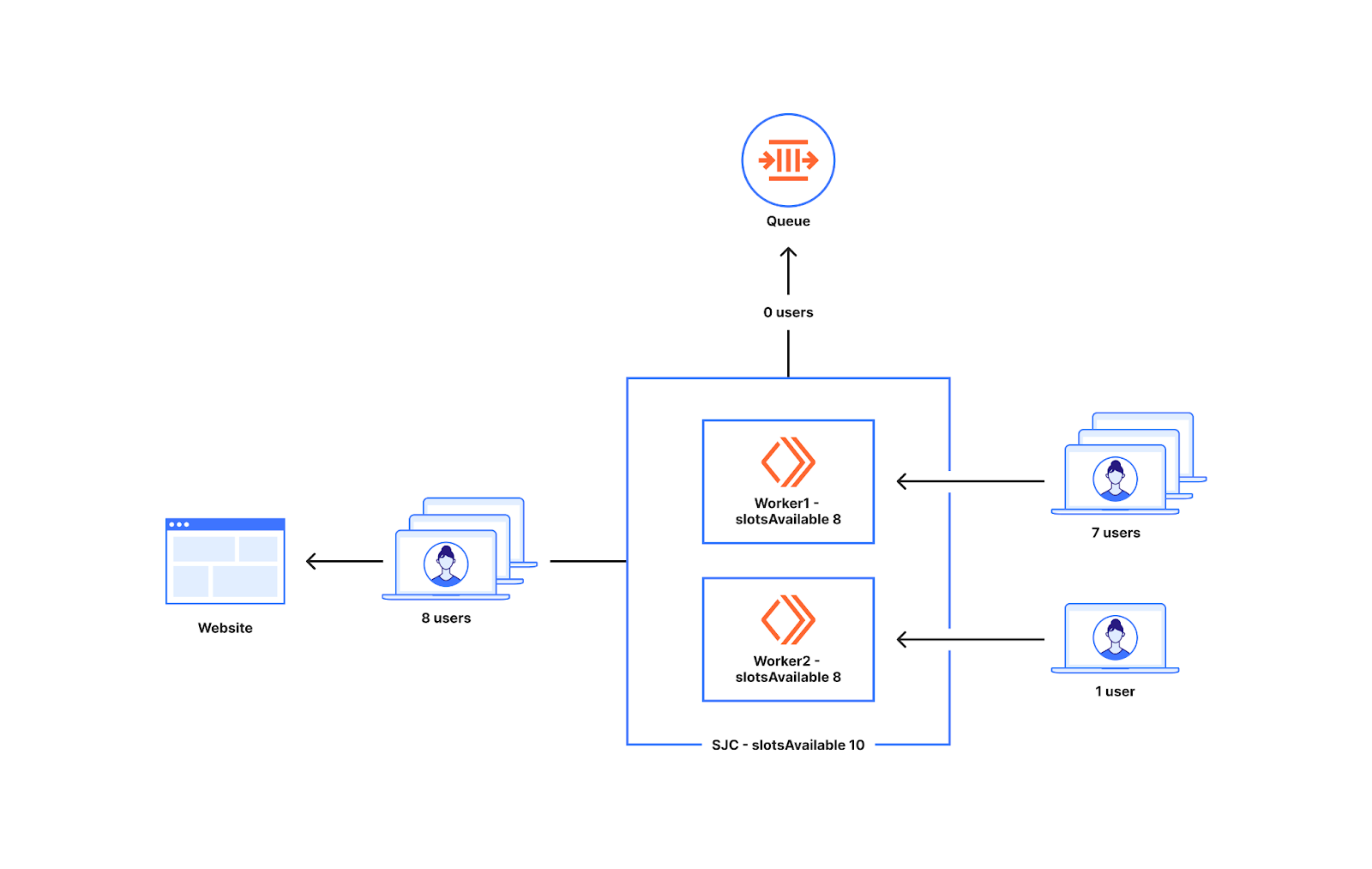
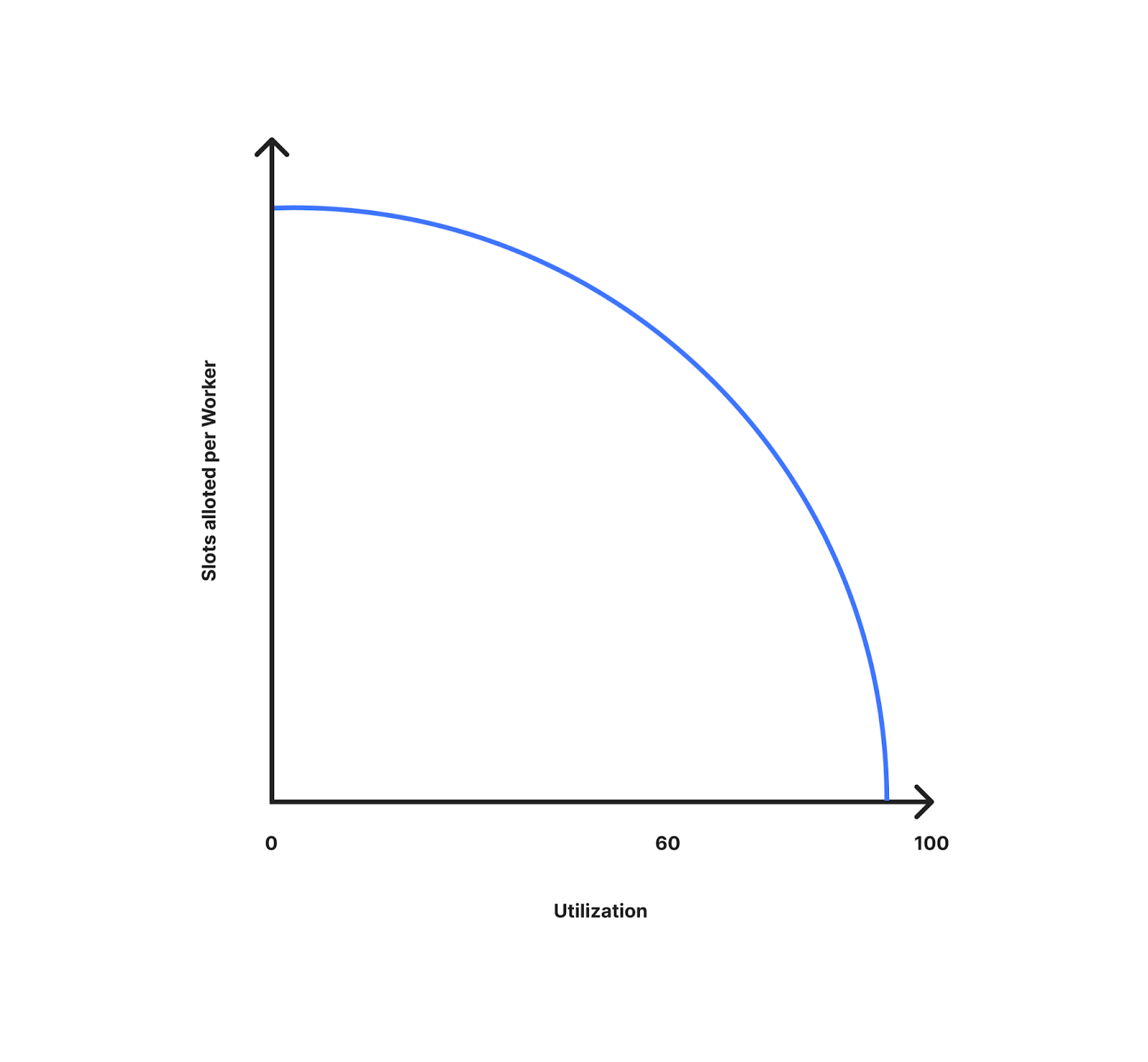
The diagram below shows how the slots allocated per worker changes with utilization (how far you are away from limits). As you can see here, we are allocating more slots per worker at lower utilization. As the utilization increases, the slots allocated per worker decrease as it’s getting closer to the limits, and we are better prepared for spikes in traffic. At 10% utilization every worker gets close to the slots available for the data center. As the utilization is close to 100% it becomes close to the slots available divided by worker count in the data center.
How do we achieve more slots at lower utilization?
This section delves into the mathematics which helps us get there. If you are not interested in these details, meet us at the “Risk of over provisioning” section.
To understand this further, let's revisit the previous example where requests come to the Delhi data center. The activeUsers value is 50, so utilization is 50/200 which is around 25%.
{ "activeUsers": 50, "globalWorkersActive": 10, "dataCenterWorkersActive": 1, "trafficHistory": { "Mon, 11 Sep 2023 11:44:00 GMT": { San Jose: 20/200, // 10% London: 30/200, // 15% Anywhere: 150/200 // 75% } }
}The idea is to allocate more slots at lower utilization levels. This ensures that customers do not see unexpected queueing behaviors when traffic is far away from limits. At time Mon, 11 Sep 2023 11:45:54 GMT requests to Delhi are at 25% utilization based on the local state key.
To allocate more slots to be available at lower utilization we added a workerMultiplier which moves proportionally to the utilization. At lower utilization the multiplier is lower and at higher utilization it is close to one.
workerMultiplier = (utilization)^curveFactor
adaptedWorkerCount = actualWorkerCount * workerMultiplierutilization - how far away from the limits you are.
curveFactor - is the exponent which can be adjusted which decides how aggressive we are with the distribution of extra budgets at lower worker counts. To understand this let's look at the graph of how y = x and y = x^2 looks between values 0 and 1.
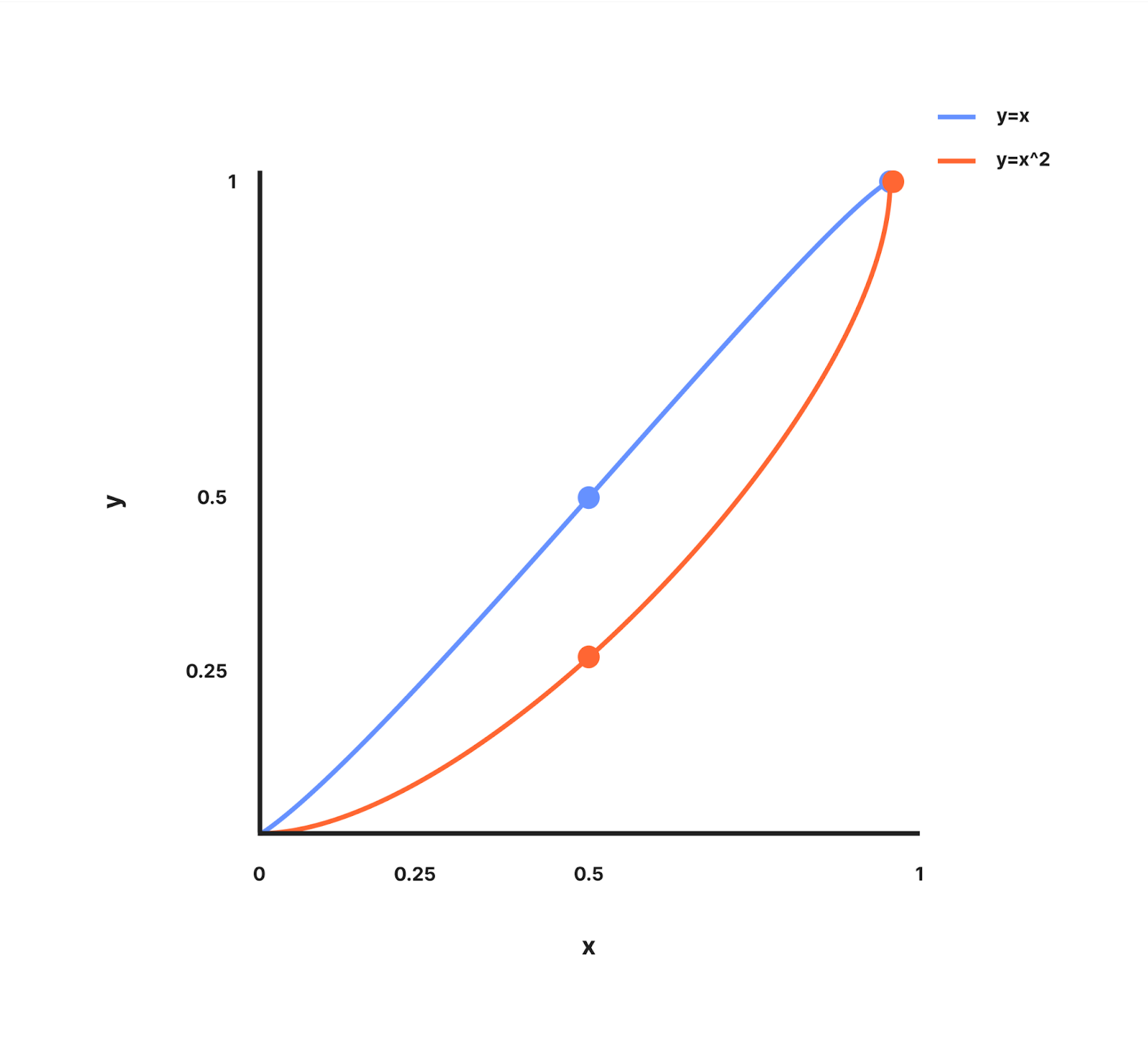
The graph for y=x is a straight line passing through (0, 0) and (1, 1).
The graph for y=x^2 is a curved line where y increases slower than x when x < 1 and passes through (0, 0) and (1, 1)
Using the concept of how the curves work, we derived the formula for workerCountMultiplier where y=workerCountMultiplier, x=utilization and curveFactor is the power which can be adjusted which decides how aggressive we are with the distribution of extra budgets at lower worker counts. When curveFactor is 1, the workerMultiplier is equal to the utilization.
Let's come back to the example we discussed before and see what the value of the curve factor will be. At time Mon, 11 Sep 2023 11:45:54 GMT requests to Delhi are at 25% utilization based on the local state key. The Anywhere slots are divided among all the active workers in the globe as any worker around the world can take a part of this pie. i.e. 75% of the remaining 150 slots (113).
globalWorkersActive is 10 when we look at the waiting room state. In this case we do not divide the 113 slots by 10 but instead divide by the adapted worker count which is globalWorkersActive * workerMultiplier. If curveFactor is 1, the workerMultiplier is equal to the utilization which is at 25% or 0.25.
So effective workerCount = 10 * 0.25 = 2.5
So, every active worker can send as many as 113/2.5 which is approximately 45 users. The first 45 users that come to a worker in the minute Mon, 11 Sep 2023 11:45:00 GMT gets admitted to the origin. The extra users get queued.
Therefore, at lower utilization (when traffic is farther from the limits) each worker gets more slots. But, if the sum of slots are added up, there is a higher chance of exceeding the overall limit.
Risk of over provisioning
The method of giving more slots at lower limits decreases the chances of queuing when traffic is low relative to traffic limits. However, at lower utilization levels a uniform spike happening around the world could cause more users to go into the origin than expected. The diagram below shows the case where this can be an issue. As you can see the slots available are ten for the data center. At 10% utilization we discussed before, each worker can have eight slots each. If eight users show up at one worker and seven show up at another, we will be sending fifteen users to the website when only ten are the maximum available slots for the data center.
With the range of customers and types of traffic we have, we were able to see cases where this became a problem. A traffic spike from low utilization levels could cause overshooting of the global limits. This is because we are over provisioned at lower limits and this increases the risk of significantly exceeding traffic limits. We needed to implement a safer approach which would not cause limits to be exceeded while also decreasing the chance of queueing when traffic is low relative to traffic limits.
Taking a step back and thinking about our approach, one of the assumptions we had was that the traffic in a data center directly correlates to the worker count that is found in a data center. In practice what we found is that this was not true for all customers. Even if the traffic correlates to the worker count, the new users going to the workers in the data centers may not correlate. This is because the slots we allocate are for new users but the traffic that a data center sees consists of both users who are already on the website and new users trying to go to the website.
In the next section we are talking about an approach where worker counts do not get used and instead workers communicate with other workers in the data center. For that we introduced a new service which is a durable object counter.
Decrease the number of times we divide the slots by introducing Data Center Counters
From the example above, we can see that overprovisioning at the worker level has the risk of using up more slots than what is allotted for a data center. If we do not over provision at low levels we have the risk of queuing users way before their configured limits are reached which we discussed first. So there has to be a solution which can achieve both these things.
The overprovisioning was done so that the workers do not run out of slots quickly when an uneven number of new users reach a bunch of workers. If there is a way to communicate between two workers in a data center, we do not need to divide slots among workers in the data center based on worker count. For that communication to take place, we introduced counters. Counters are a bunch of small durable object instances that do counting for a set of workers in the data center.
To understand how it helps with avoiding usage of worker counts, let's check the diagram below. There are two workers talking to a Data Center Counter below. Just as we discussed before, the workers let users through to the website based on the waiting room state. The count of the number of users let through was stored in the memory of the worker before. By introducing counters, it is done in the Data Center Counter. Whenever a new user makes a request to the worker, the worker talks to the counter to know the current value of the counter. In the example below for the first new request to the worker the counter value received is 9. When a data center has 10 slots available, that will mean the user can go to the website. If the next worker receives a new user and makes a request just after that, it will get a value 10 and based on the slots available for the worker, the user will get queued.
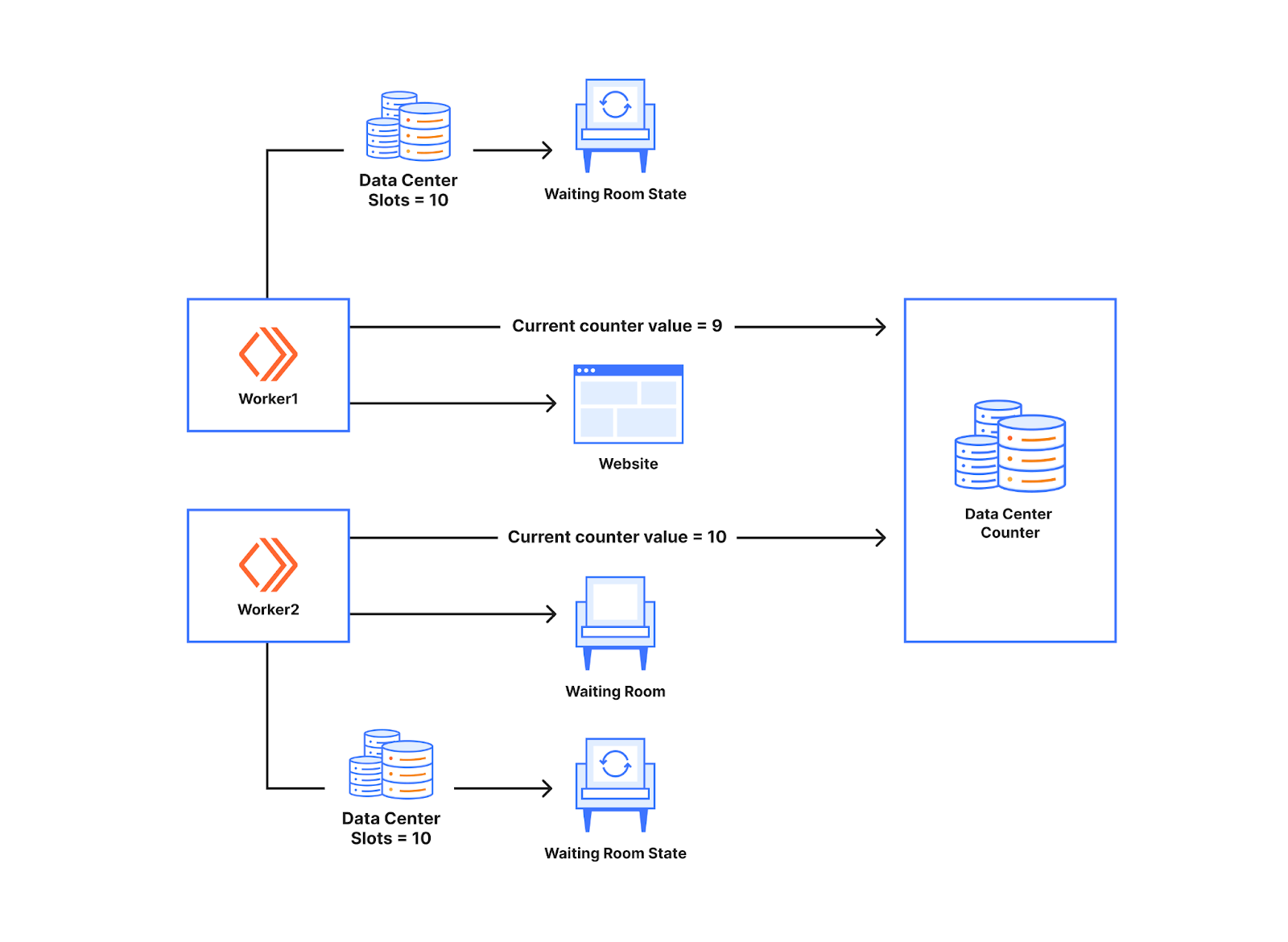
The Data Center Counter acts as a point of synchronization for the workers in the waiting room. Essentially, this enables the workers to talk to each other without really talking to each other directly. This is similar to how a ticketing counter works. Whenever one worker lets someone in, they request tickets from the counter, so another worker requesting the tickets from the counter will not get the same ticket number. If the ticket value is valid, the new user gets to go to the website. So when different numbers of new users show up at workers, we will not over allocate or under allocate slots for the worker as the number of slots used is calculated by the counter which is for the data center.
The diagram below shows the behavior when an uneven number of new users reach the workers, one gets seven new users and the other worker gets one new user. All eight users that show up at the workers in the diagram below get to the website as the slots available for the data center is ten which is below ten.
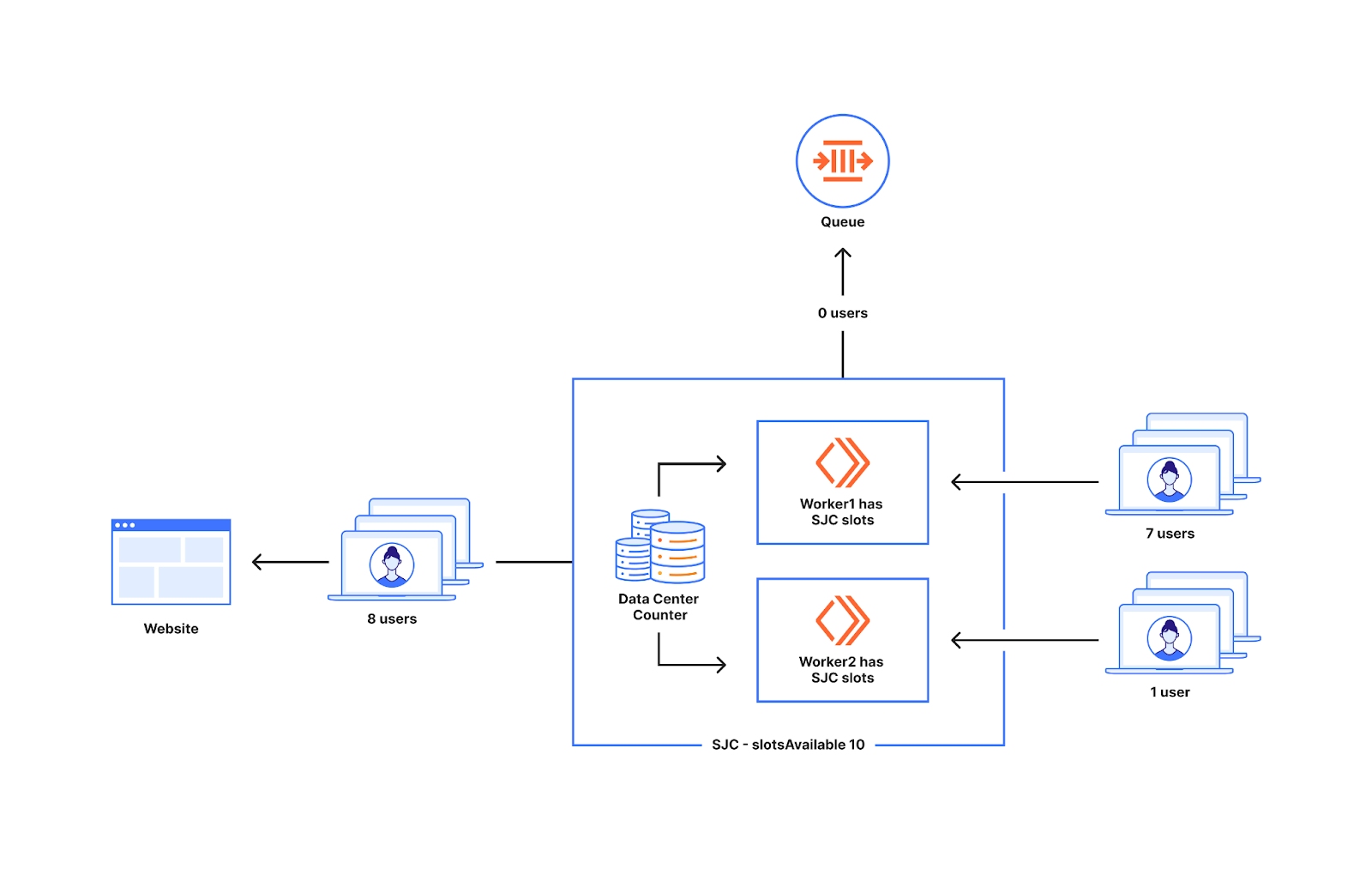
This also does not cause excess users to get sent to the website as we do not send extra users when the counter value equals the slotsAvailable for the data center. Out of the fifteen users that show up at the workers in the diagram below ten will get to the website and five will get queued which is what we would expect.
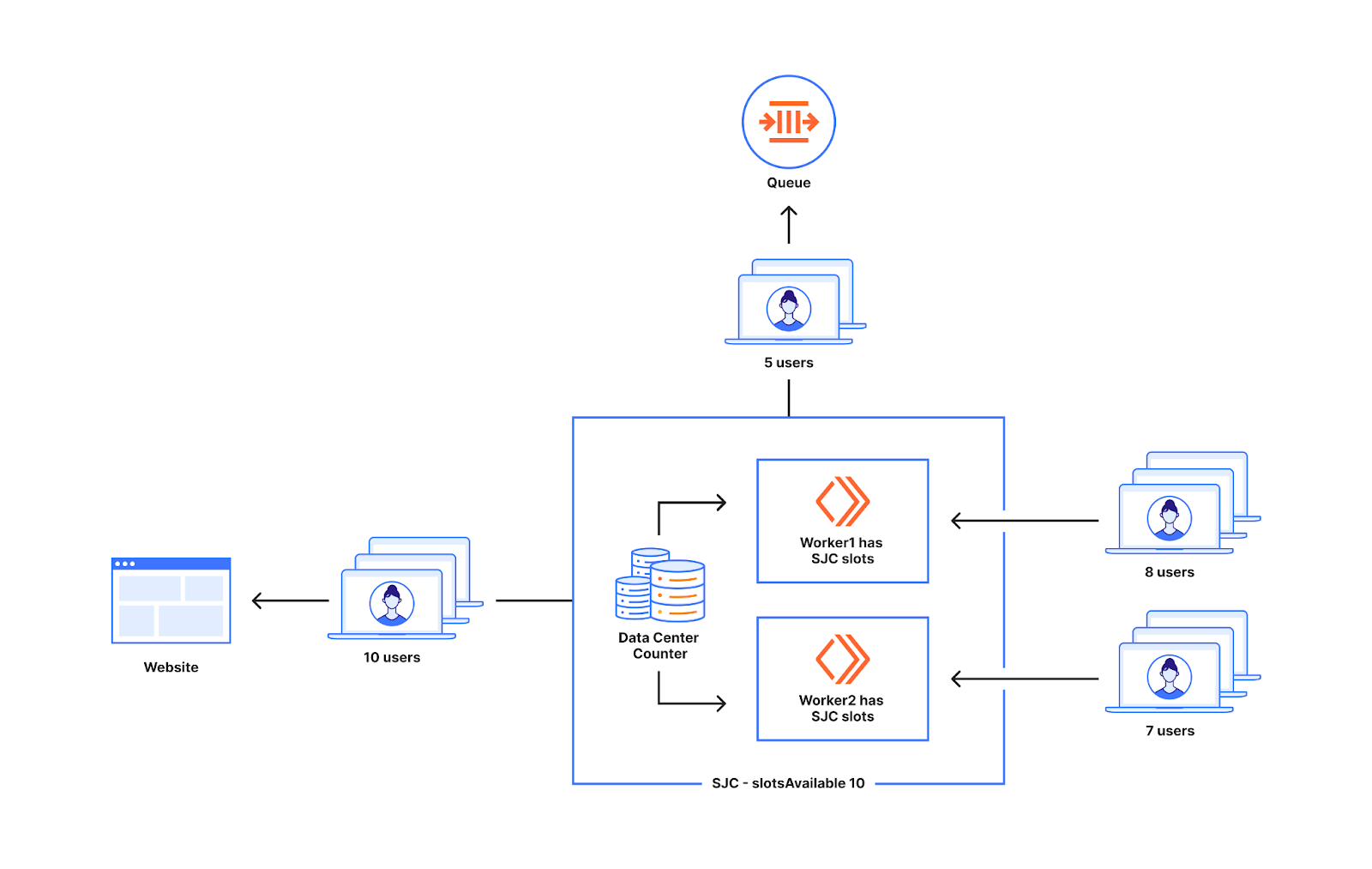
Risk of over provisioning at lower utilization also does not exist as counters help workers to communicate with each other.
To understand this further, let's look at the previous example we talked about and see how it works with the actual waiting room state.
The waiting room state for the customer is as follows.
{ "activeUsers": 50, "globalWorkersActive": 10, "dataCenterWorkersActive": 3, "trafficHistory": { "Mon, 11 Sep 2023 11:44:00 GMT": { San Jose: 20/200, // 10% London: 30/200, // 15% Anywhere: 150/200 // 75% } }
}The objective is to not divide the slots among workers so that we don’t need to use that information from the state. At time Mon, 11 Sep 2023 11:45:54 GMT requests come to San Jose. So, we can send 10% of 150 slots available from San Jose which is 15.
The durable object counter at San Jose keeps returning the counter value it is at right now for every new user that reaches the data center. It will increment the value by 1 after it returns to a worker. So the first 15 new users that come to the worker get a unique counter value. If the value received for a user is less than 15 they get to use the slots at the data center.
Once the slots available for the data center runs out, the users can make use of the slots allocated for Anywhere data-centers as these are not reserved for any particular data center. Once a worker in San Jose gets a ticket value that says 15, it realizes that it's not possible to go to the website using the slots from San Jose.
The Anywhere slots are available for all the active workers in the globe i.e. 75% of the remaining 150 slots (113). The Anywhere slots are handled by a durable object that workers from different data centers can talk to when they want to use Anywhere slots. Even if 128 (113 + 15) users end up going to the same worker for this customer we will not queue them. This increases the ability of Waiting Room to handle an uneven number of new users going to workers around the world which in turn helps the customers to queue close to the configured limits.
Why do counters work well for us?
When we built the Waiting Room, we wanted the decisions for entry into the website to be made at the worker level itself without talking to other services when the request is in flight to the website. We made that choice to avoid adding latency to user requests. By introducing a synchronization point at a durable object counter, we are deviating from that by introducing a call to a durable object counter.
However, the durable object for the data center stays within the same data center. This leads to minimal additional latency which is usually less than 10 ms. For the calls to the durable object that handles Anywhere data centers, the worker may have to cross oceans and long distances. This could cause the latency to be around 60 or 70 ms in those cases. The 95th percentile values shown below are higher because of calls that go to farther data centers.
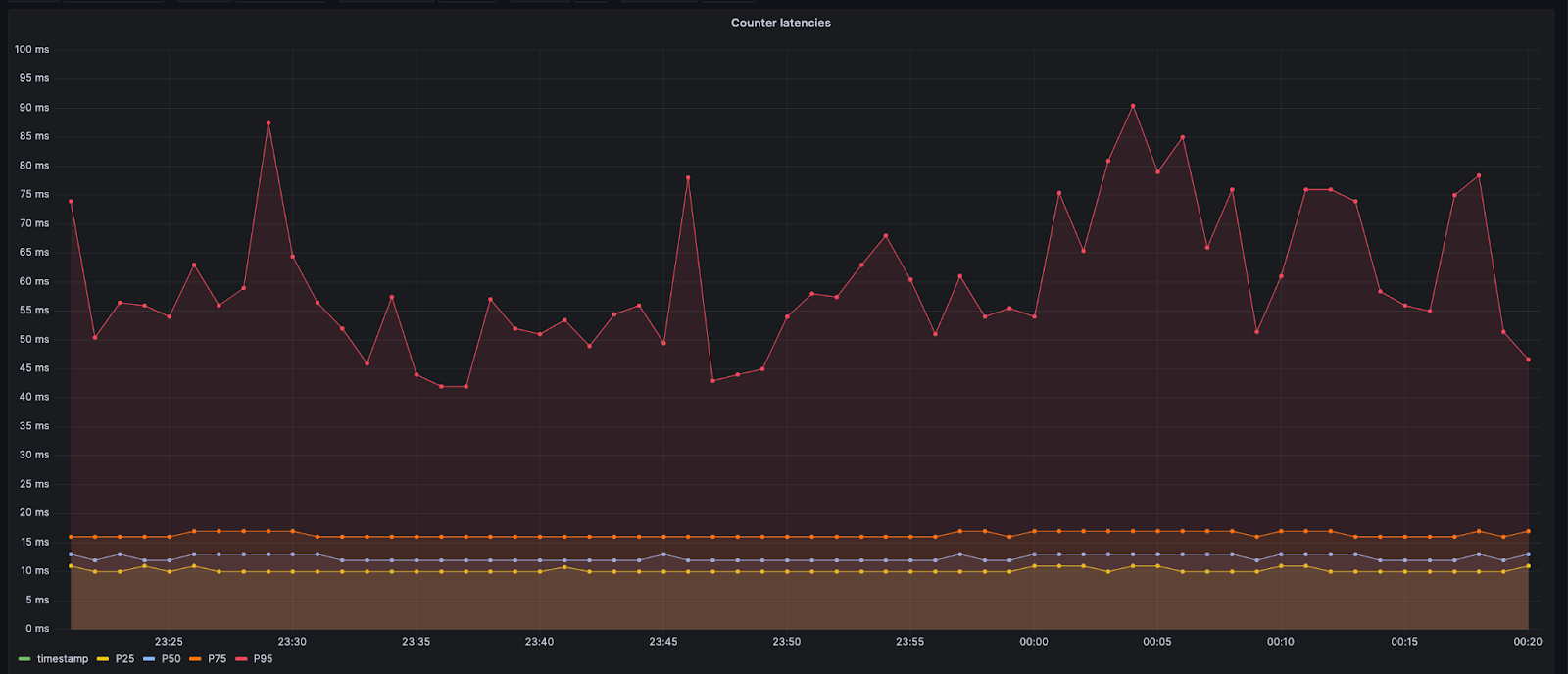
The design decision to add counters adds a slight extra latency for new users going to the website. We deemed the trade-off acceptable because this reduces the number of users that get queued before limits are reached. In addition, the counters are only required when new users try to go into the website. Once new users get to the origin, they get entry directly from workers as the proof of entry is available in the cookies that the customers come with, and we can let them in based on that.
Counters are really simple services which do simple counting and do nothing else. This keeps the memory and CPU footprint of the counters minimal. Moreover, we have a lot of counters around the world handling the coordination between a subset of workers.This helps counters to successfully handle the load for the synchronization requirements from the workers. These factors add up to make counters a viable solution for our use case.
Summary
Waiting Room was designed with our number one priority in mind–to ensure that our customers’ sites remain up and running, no matter the volume or ramp up of legitimate traffic. Waiting Room runs on every server in Cloudflare’s network, which spans over 300 cities in more than 100 countries. We want to make sure, for every new user, the decision whether to go to the website or the queue is made with minimal latency and is done at the right time. This decision is a hard one as queuing too early at a data center can cause us to queue earlier than the customer set limits. Queuing too late can cause us to overshoot the customer set limits.
With our initial approach where we divide slots among our workers evenly we were sometimes queuing too early but were pretty good at respecting customer set limits. Our next approach of giving more slots at low utilization (low traffic levels compared to customer limits) ensured that we did better at the cases where we queued earlier than the customer set limits as every worker has more slots to work with at each worker. But as we have seen, this made us more likely to overshoot when a sudden spike in traffic occurred after a period of low utilization.
With counters we are able to get the best of both worlds as we avoid the division of slots by worker counts. Using counters we are able to ensure that we do not queue too early or too late based on the customer set limits. This comes at the cost of a little bit of latency to every request from a new user which we have found to be negligible and creates a better user experience than getting queued early.
We keep iterating on our approach to make sure we are always queuing people at the right time and above all protecting your website. As more and more customers are using the waiting room, we are learning more about different types of traffic and that is helping the product be better for everyone.