Assembly within! BPF tail calls on x86 and ARM
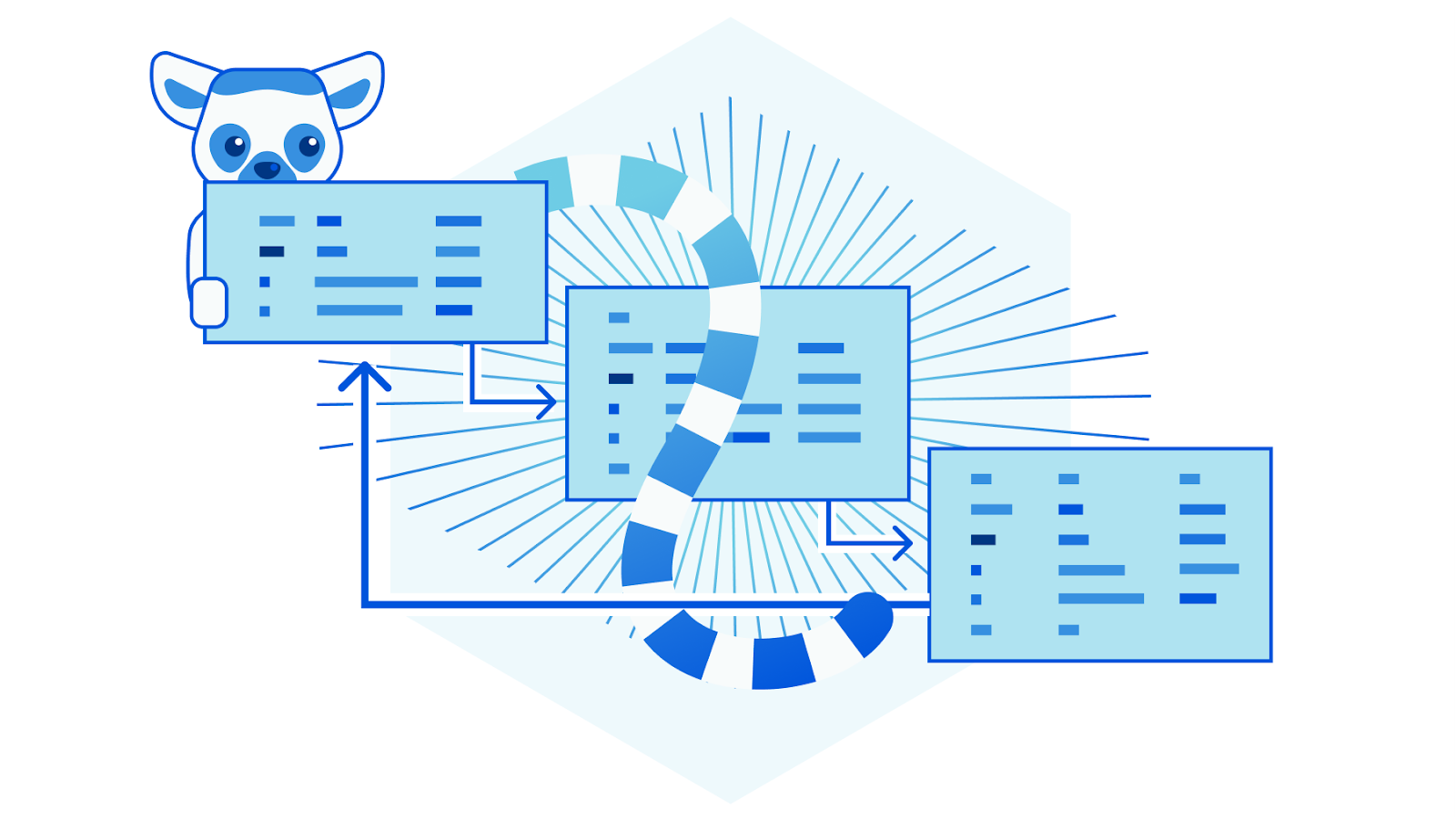
Early on when we learn to program, we get introduced to the concept of recursion. And that it is handy for computing, among other things, sequences defined in terms of recurrences. Such as the famous Fibonnaci numbers - Fn = Fn-1 + Fn-2.
Later on, perhaps when diving into multithreaded programming, we come to terms with the fact that the stack space for call frames is finite. And that there is an “okay” way and a “cool” way to calculate the Fibonacci numbers using recursion:
// fib_okay.c
#include <stdint.h>
uint64_t fib(uint64_t n)
{ if (n == 0 || n == 1) return 1; return fib(n - 1) + fib(n - 2);
}Listing 1. An okay Fibonacci number generator implementation
// fib_cool.c
#include <stdint.h>
static uint64_t fib_tail(uint64_t n, uint64_t a, uint64_t b)
{ if (n == 0) return a; if (n == 1) return b; return fib_tail(n - 1, b, a + b);
}
uint64_t fib(uint64_t n)
{ return fib_tail(n, 1, 1);
}Listing 2. A better version of the same
If we take a look at the machine code the compiler produces, the “cool” variant translates to a nice and tight sequence of instructions:
⚠ DISCLAIMER: This blog post is assembly-heavy. We will be looking at assembly code for x86-64, arm64 and BPF architectures. If you need an introduction or a refresher, I can recommend “Low-Level Programming” by Igor Zhirkov for x86-64, and “Programming with 64-Bit ARM Assembly Language” by Stephen Smith for arm64. For BPF, see the Linux kernel documentation.
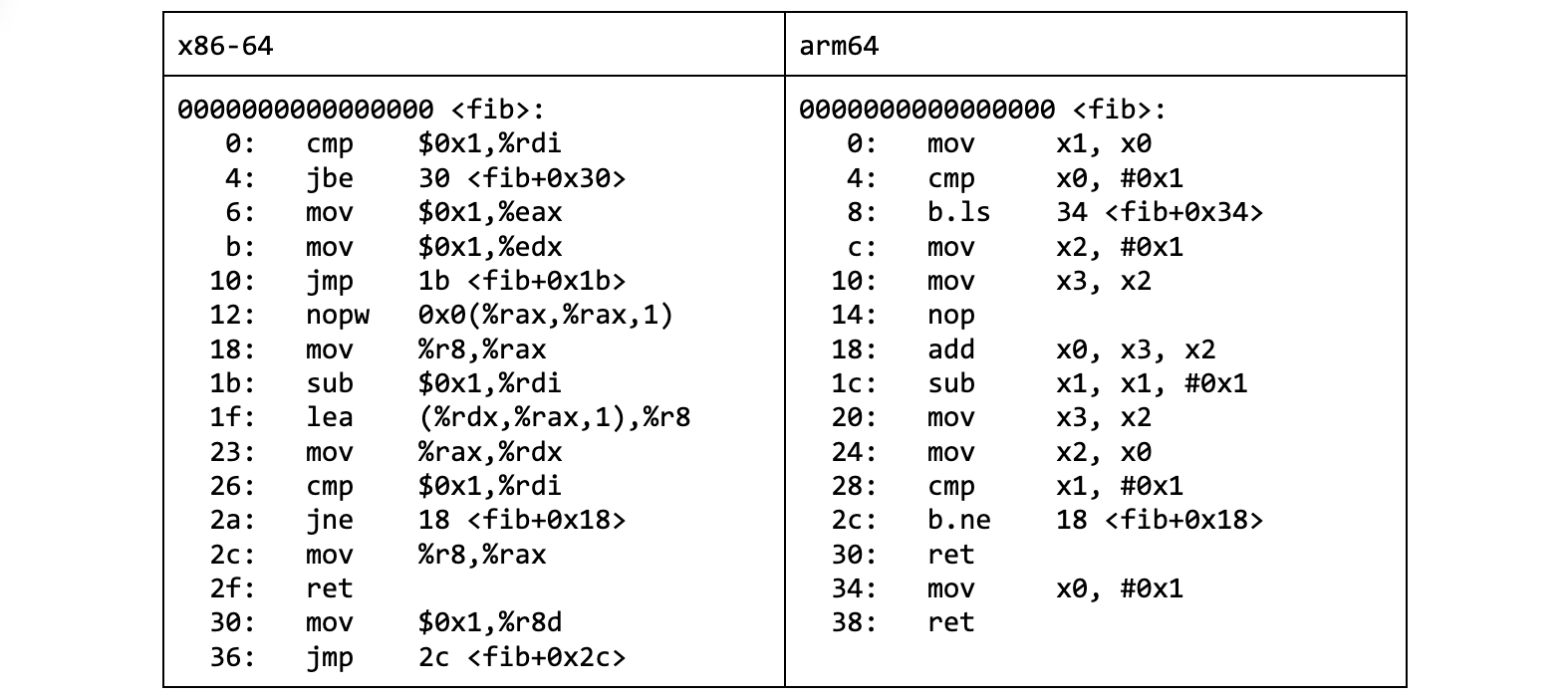
Listing 3. fib_cool.c compiled for x86-64 and arm64
The “okay” variant, disappointingly, leads to more instructions than a listing can fit. It is a spaghetti of basic blocks.

But more importantly, it is not free of x86 call instructions.
$ objdump -d fib_okay.o | grep call 10c: e8 00 00 00 00 call 111 <fib+0x111>
$ objdump -d fib_cool.o | grep call
$This has an important consequence - as fib recursively calls itself, the stacks keep growing. We can observe it with a bit of help from the debugger.
$ gdb --quiet --batch --command=trace_rsp.gdb --args ./fib_okay 6
Breakpoint 1 at 0x401188: file fib_okay.c, line 3.
[Thread debugging using libthread_db enabled]
Using host libthread_db library "/lib64/libthread_db.so.1".
n = 6, %rsp = 0xffffd920
n = 5, %rsp = 0xffffd900
n = 4, %rsp = 0xffffd8e0
n = 3, %rsp = 0xffffd8c0
n = 2, %rsp = 0xffffd8a0
n = 1, %rsp = 0xffffd880
n = 1, %rsp = 0xffffd8c0
n = 2, %rsp = 0xffffd8e0
n = 1, %rsp = 0xffffd8c0
n = 3, %rsp = 0xffffd900
n = 2, %rsp = 0xffffd8e0
n = 1, %rsp = 0xffffd8c0
n = 1, %rsp = 0xffffd900
13
[Inferior 1 (process 50904) exited normally]
$While the “cool” variant makes no use of the stack.
$ gdb --quiet --batch --command=trace_rsp.gdb --args ./fib_cool 6
Breakpoint 1 at 0x40118a: file fib_cool.c, line 13.
[Thread debugging using libthread_db enabled]
Using host libthread_db library "/lib64/libthread_db.so.1".
n = 6, %rsp = 0xffffd938
13
[Inferior 1 (process 50949) exited normally]
$Where did the calls go?
The smart compiler turned the last function call in the body into a regular jump. Why was it allowed to do that?
It is the last instruction in the function body we are talking about. The caller stack frame is going to be destroyed right after we return anyway. So why keep it around when we can reuse it for the callee’s stack frame?
This optimization, known as tail call elimination, leaves us with no function calls in the “cool” variant of our fib implementation. There was only one call to eliminate - right at the end.
Once applied, the call becomes a jump (loop). If assembly is not your second language, decompiling the fib_cool.o object file with Ghidra helps see the transformation:
long fib(ulong param_1)
{ long lVar1; long lVar2; long lVar3; if (param_1 < 2) { lVar3 = 1; } else { lVar3 = 1; lVar2 = 1; do { lVar1 = lVar3; param_1 = param_1 - 1; lVar3 = lVar2 + lVar1; lVar2 = lVar1; } while (param_1 != 1); } return lVar3;
}Listing 4. fib_cool.o decompiled by Ghidra
This is very much desired. Not only is the generated machine code much shorter. It is also way faster due to lack of calls, which pop up on the profile for fib_okay.
But I am no performance ninja and this blog post is not about compiler optimizations. So why am I telling you about it?

{kind=link}
Tail calls in BPF
The concept of tail call elimination made its way into the BPF world. Although not in the way you might expect. Yes, the LLVM compiler does get rid of the trailing function calls when building for -target bpf. The transformation happens at the intermediate representation level, so it is backend agnostic. This can save you some BPF-to-BPF function calls, which you can spot by looking for call -N instructions in the BPF assembly.
However, when we talk about tail calls in the BPF context, we usually have something else in mind. And that is a mechanism, built into the BPF JIT compiler, for chaining BPF programs.
We first adopted BPF tail calls when building our XDP-based packet processing pipeline. Thanks to it, we were able to divide the processing logic into several XDP programs. Each responsible for doing one thing.
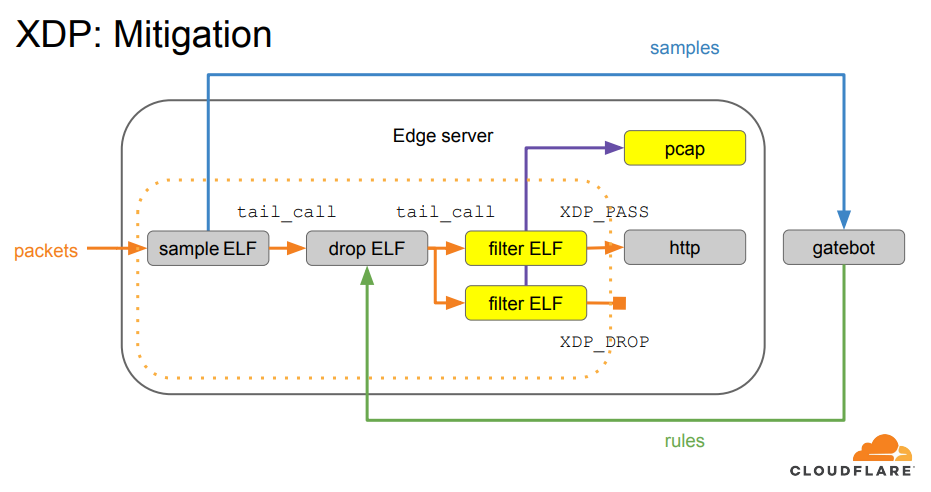
BPF tail calls have served us well since then. But they do have their caveats. Until recently it was impossible to have both BPF tails calls and BPF-to-BPF function calls in the same XDP program on arm64, which is one of the supported architectures for us.
Why? Before we get to that, we have to clarify what a BPF tail call actually does.
A tail call is a tail call is a tail call
BPF exposes the tail call mechanism through the bpf_tail_call helper, which we can invoke from our BPF code. We don’t directly point out which BPF program we would like to call. Instead, we pass it a BPF map (a container) capable of holding references to BPF programs (BPF_MAP_TYPE_PROG_ARRAY), and an index into the map.
long bpf_tail_call(void *ctx, struct bpf_map *prog_array_map, u32 index) Description This special helper is used to trigger a "tail call", or in other words, to jump into another eBPF program. The same stack frame is used (but values on stack and in reg‐ isters for the caller are not accessible to the callee). This mechanism allows for program chaining, either for raising the maximum number of available eBPF instructions, or to execute given programs in conditional blocks. For security reasons, there is an upper limit to the number of successive tail calls that can be performed.At first glance, this looks somewhat similar to the execve(2) syscall. It is easy to mistake it for a way to execute a new program from the current program context. To quote the excellent BPF and XDP Reference Guide from the Cilium project documentation:
Tail calls can be seen as a mechanism that allows one BPF program to call another, without returning to the old program. Such a call has minimal overhead as unlike function calls, it is implemented as a long jump, reusing the same stack frame.
But once we add BPF function calls into the mix, it becomes clear that the BPF tail call mechanism is indeed an implementation of tail call elimination, rather than a way to replace one program with another:
Tail calls, before the actual jump to the target program, will unwind only its current stack frame. As we can see in the example above, if a tail call occurs from within the sub-function, the function’s (func1) stack frame will be present on the stack when a program execution is at func2. Once the final function (func3) function terminates, all the previous stack frames will be unwinded and control will get back to the caller of BPF program caller.
Alas, one with sometimes slightly surprising semantics. Consider the code like below, where a BPF function calls the bpf_tail_call() helper:
struct { __uint(type, BPF_MAP_TYPE_PROG_ARRAY); __uint(max_entries, 1); __uint(key_size, sizeof(__u32)); __uint(value_size, sizeof(__u32));
} bar SEC(".maps");
SEC("tc")
int serve_drink(struct __sk_buff *skb __unused)
{ return 0xcafe;
}
static __noinline
int bring_order(struct __sk_buff *skb)
{ bpf_tail_call(skb, &bar, 0); return 0xf00d;
}
SEC("tc")
int server1(struct __sk_buff *skb)
{ return bring_order(skb);
}
SEC("tc")
int server2(struct __sk_buff *skb)
{ __attribute__((musttail)) return bring_order(skb);
}We have two seemingly not so different BPF programs - server1() and server2(). They both call the same BPF function bring_order(). The function tail calls into the serve_drink() program, if the bar[0] map entry points to it (let’s assume that).
Do both server1 and server2 return the same value? Turns out that - no, they don’t. We get a hex